Humans from an early age are able to effortlessly comprehend complex visual scenes which forms the bases for learning more advanced capabilities. Similarly, intelligent systems such as robots should have the ability to coherently understand visual scenes at both the fundamental pixel-level as well as at the distinctive object instance level. This enables them to perceive and reason about the environment holistically which facilitates interaction. Such modeling ability is a crucial enabler that can revolutionize several diverse applications including robotics, self-driving cars, augmented reality, and biomedical imaging.
EfficientPS Demo
Deep Convolutional Neural Networks for Panoptic Segmentation
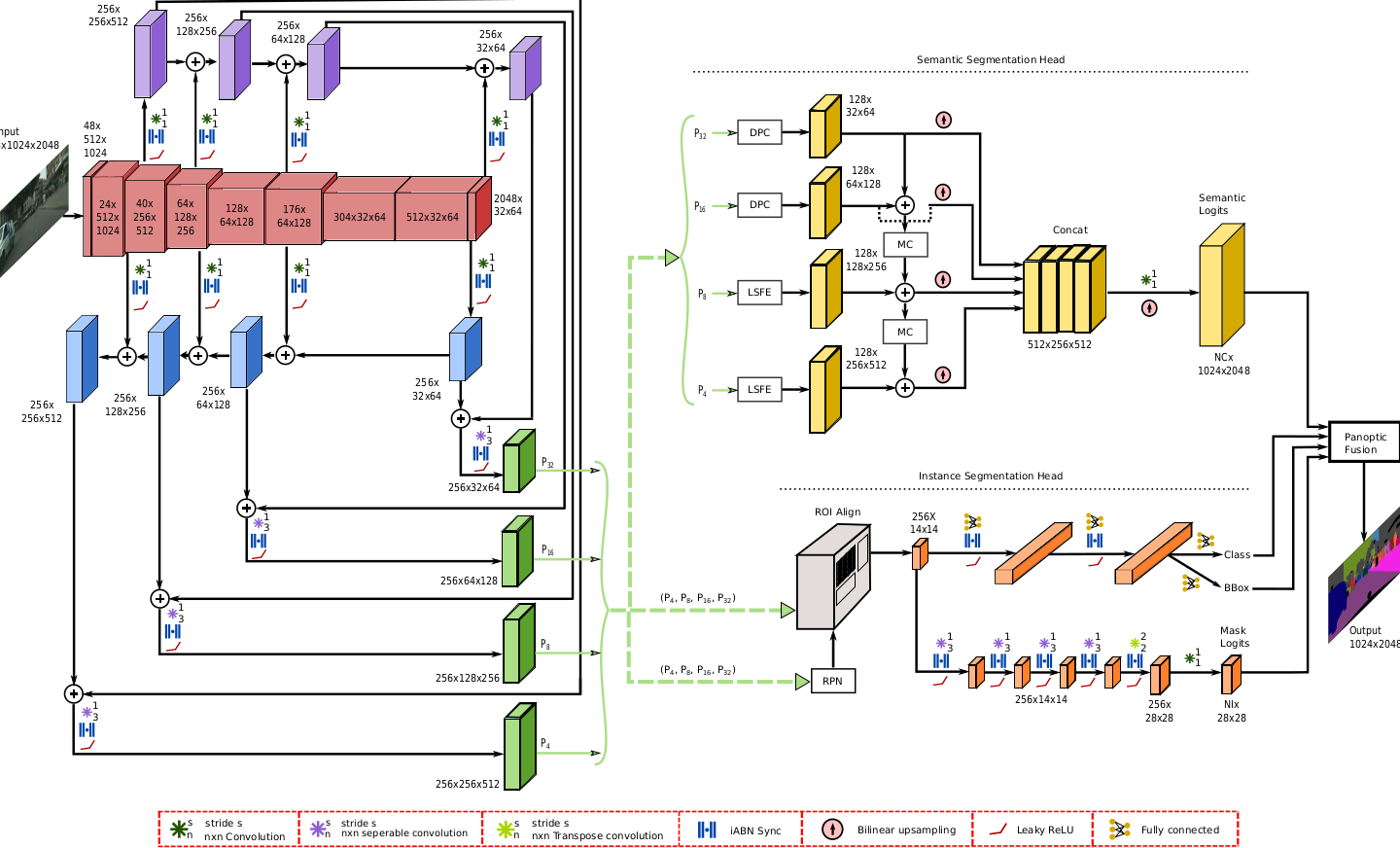
This demo shows the panoptic segmentation performance of our EfficeintPS model trained on four challenging urban scene understanding datasets. EfficientPS is currently ranked #1 for panoptic segmentation on standard benchmark datasets such as Cityscapes, KITTI, Mapillary Vistas, and IDD. Additionally, EfficientPS is also ranked #2 on the Cityscapes semantic segmentation benchmark as well as #2 on the Cityscapes instance segmentation benchmark, among the published methods. To learn more about panoptic segmentation and the approach employed, please see the Technical Approach. View the demo by selecting a dataset to load from the drop down box below and click on an image in the carosel to see live results. The results are shown as an overlay of panoptic segmentation over the input image. The colors of the overlay denote what semantic category that the pixel belongs to and the instances of objects are indicated with a white boundary.
Please Select a Model:
Selected Dataset:
Cityscapes